確認(rèn)過眼神,是被大劇院pick的媒資數(shù)據(jù)存儲(chǔ) 數(shù)據(jù)處理與存儲(chǔ)服務(wù)解析
在數(shù)字時(shí)代的浪潮中,文化藝術(shù)的傳承與創(chuàng)新日益依賴于先進(jìn)的技術(shù)支持。當(dāng)一座現(xiàn)代化的大劇院“確認(rèn)過眼神”,選擇了一套專業(yè)的媒資數(shù)據(jù)存儲(chǔ)與處理服務(wù)時(shí),這背后不僅是技術(shù)的落地,更是一場關(guān)于藝術(shù)資產(chǎn)數(shù)字化管理、智能化應(yīng)用與長久保存的深刻變革。
媒資數(shù)據(jù),對于大劇院而言,是其最核心的數(shù)字資產(chǎn)。它涵蓋了一場場精彩演出的高清錄像、音頻記錄、珍貴的排練花絮、歷史劇目的檔案資料、舞美設(shè)計(jì)圖紙、宣傳物料以及藝術(shù)家訪談等海量、多格式的非結(jié)構(gòu)化數(shù)據(jù)。這些數(shù)據(jù)不僅具有極高的藝術(shù)價(jià)值、歷史價(jià)值,也蘊(yùn)含著巨大的商業(yè)開發(fā)與再利用潛力。傳統(tǒng)的存儲(chǔ)方式往往面臨容量瓶頸、檢索困難、數(shù)據(jù)安全風(fēng)險(xiǎn)以及長期保存的挑戰(zhàn)。因此,一套能夠被大劇院“pick”的專業(yè)數(shù)據(jù)處理與存儲(chǔ)服務(wù),必須精準(zhǔn)地解決這些痛點(diǎn)。
數(shù)據(jù)處理:從海量信息到智能資產(chǎn)
專業(yè)的服務(wù)首先體現(xiàn)在高效的數(shù)據(jù)處理能力上。當(dāng)演出錄制生成的原始數(shù)據(jù)涌入系統(tǒng),服務(wù)需要提供強(qiáng)大的數(shù)據(jù)采集、轉(zhuǎn)碼與編目能力。
- 自動(dòng)化采集與轉(zhuǎn)碼:支持從多種專業(yè)錄制設(shè)備無縫接入,并自動(dòng)將不同格式、碼流的音視頻文件轉(zhuǎn)碼為適合長期保存、網(wǎng)絡(luò)傳輸及多種終端播放的統(tǒng)一格式,確保數(shù)據(jù)的一致性與可用性。
- 智能化編目與元數(shù)據(jù)提取:利用人工智能技術(shù),如語音識別、人臉識別、場景識別等,對音視頻內(nèi)容進(jìn)行深度分析,自動(dòng)提取關(guān)鍵元數(shù)據(jù)(如出場人物、表演段落、情感基調(diào)、道具場景等)。這能將非結(jié)構(gòu)化的視聽內(nèi)容,轉(zhuǎn)化為結(jié)構(gòu)化的、可檢索的“智能資產(chǎn)”。
- 內(nèi)容管理與檢索:基于豐富的元數(shù)據(jù),構(gòu)建強(qiáng)大的內(nèi)容管理系統(tǒng)。工作人員可以通過關(guān)鍵詞、時(shí)間點(diǎn)、人物、劇目類型等多種維度,在數(shù)百萬小時(shí)的資料庫中實(shí)現(xiàn)秒級精準(zhǔn)檢索,極大提升藝術(shù)創(chuàng)作、研究和宣傳的效率。
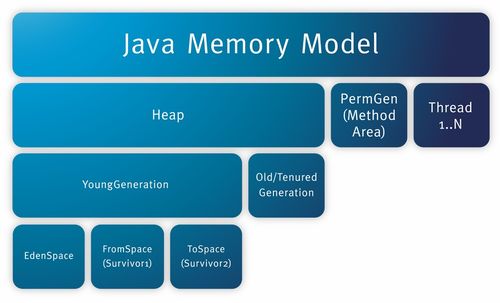
數(shù)據(jù)存儲(chǔ):安全、可靠與彈性擴(kuò)展的基石
存儲(chǔ)是承載這一切的基石。被大劇院青睞的存儲(chǔ)方案,必然是安全、可靠且面向未來的。
- 分級存儲(chǔ)架構(gòu):采用在線、近線、離線相結(jié)合的分級存儲(chǔ)策略。高頻訪問的熱點(diǎn)數(shù)據(jù)(如近期熱門劇目)存放于高速在線存儲(chǔ),確保快速調(diào)用;不常訪問的溫冷數(shù)據(jù)遷移至成本更優(yōu)的近線或磁帶庫進(jìn)行歸檔,在需要時(shí)也能快速恢復(fù)。這實(shí)現(xiàn)了性能與成本的最佳平衡。
- 高可靠與高可用性:通過多副本、糾刪碼等技術(shù),確保數(shù)據(jù)在硬件故障時(shí)不會(huì)丟失。系統(tǒng)架構(gòu)本身具備高可用性,避免單點(diǎn)故障,保障劇院日常運(yùn)營和在線服務(wù)不中斷。
- 彈性擴(kuò)展能力:藝術(shù)生產(chǎn)是持續(xù)的過程,數(shù)據(jù)量增長迅猛。存儲(chǔ)系統(tǒng)需具備平滑的橫向擴(kuò)展能力,能夠在不中斷業(yè)務(wù)的情況下,實(shí)現(xiàn)容量與性能的“隨需增長”,滿足劇院未來數(shù)十年的發(fā)展需求。
- 長期保存與數(shù)據(jù)安全:針對具有永久保存價(jià)值的珍貴歷史資料,提供符合國際標(biāo)準(zhǔn)的長期保存方案,防止數(shù)據(jù)因技術(shù)過時(shí)或介質(zhì)老化而損毀。通過嚴(yán)格的權(quán)限管理、訪問審計(jì)、數(shù)據(jù)加密(靜態(tài)與傳輸中)以及防勒索病毒等安全措施,為珍貴的數(shù)字資產(chǎn)構(gòu)筑銅墻鐵壁。
服務(wù)價(jià)值:賦能藝術(shù)創(chuàng)作與管理
這套被“pick”的服務(wù),其價(jià)值遠(yuǎn)不止于存儲(chǔ)本身。它賦能大劇院實(shí)現(xiàn):
- 藝術(shù)遺產(chǎn)的數(shù)字化永生:讓經(jīng)典劇目得以高質(zhì)量、永久保存,供后人研究、欣賞與再創(chuàng)作。
- 創(chuàng)作效率的提升:編導(dǎo)、舞美等創(chuàng)作人員可以快速檢索和調(diào)用歷史素材,激發(fā)靈感,加速新作品的創(chuàng)作流程。
- 運(yùn)營管理的智能化:基于數(shù)據(jù)資產(chǎn)進(jìn)行觀眾偏好分析、演出效果評估,為劇目引進(jìn)、排期和市場營銷提供數(shù)據(jù)支持。
- 商業(yè)價(jià)值的拓展:便利的素材管理為衍生品開發(fā)、在線點(diǎn)播、IP授權(quán)等多元化經(jīng)營打開了空間。
- 公共文化服務(wù)的深化:便于開展線上藝術(shù)教育、數(shù)字展覽,讓劇院資源突破物理邊界,惠及更廣泛的公眾。
當(dāng)大劇院與專業(yè)的媒資數(shù)據(jù)處理存儲(chǔ)服務(wù)“確認(rèn)過眼神”,意味著它正以科技之力,精心守護(hù)著舞臺上的每一刻輝煌,并將這些閃耀的瞬間,轉(zhuǎn)化為可傳承、可挖掘、可再創(chuàng)造的永恒數(shù)字財(cái)富。這不僅是技術(shù)的選擇,更是對藝術(shù)未來的一份鄭重承諾。
如若轉(zhuǎn)載,請注明出處:http://m.tctteq3v.cn/product/60.html
更新時(shí)間:2026-06-09 08:51:31